4.2: The Tree Window
The previous section introduced
the concepts of searches and the filter, and upcoming sections
explain the various types of search ChessDB can do for you.
Here we introduce a special search tool called the Tree window.
You can open or close the Tree using the Windows: Tree window
menu command, the Ctrl+T shortcut key, or
 on the toolbar.
on the toolbar.
The Tree window is based on the observation that a very common
search users want to do is find all games with a particular
opening position, and see what moves were played from that
position. This is what the Tree window does for you. Whenever the
current displayed position (in the main window chessboard) changes,
the Tree re-searches your database and sets the filter to contain
only the games that reach the displayed position. It also lists
all the moves played from the position, along with their relative
success rate (always from White's perspective even if Black is
to move) and other useful statistics.
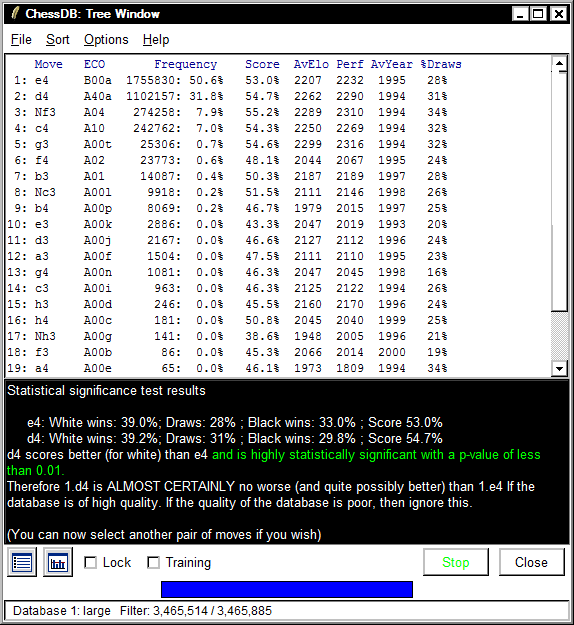
e4: White wins: 39.0%; Draws: 28% ; Black wins: 33.0% ; Score 53.0%
Scid, Chess Assistant and ChessBase all have a tree window, but ChessDB has one feature in the Tree window which is unique to ChessDB - a feature I suspect others will add! This is ChessDB's ability to show not only the score of different moves, but also whether the differences in scores between any two moves are statistically significant or not.
Testing the Statistical significance of Moves
Before describing this feature, a brief introduction to statistical significance will be given. For more detailed discussions on this, which are not needed to use the feature in ChessDB, one should search for infomation on Hypothesis Testing, p-value, Null Hypothesis or Chi-squared test.Statistical Significance - a brief introduction
It is always possible that an observed result can be just due to chance. For example, if you flip a coin 10 times, and it comes up heads 7 times, and tails 3 times, does these mean that the coin is biased? The answer is no, as that difference in score, or a larger difference (i.e. 7, 8, 9, 0, 1, 2, or 3 heads, but not 4, 5 or 6 heads) could very likely happen by chance. (The approximate probability of this can be calculated by a chi-square test and is called the p-value. The p-value in this case would be 0.3428, meaning such a result would happen more than 1 in 3 times by chance, so it is not unlikly.)
But if the coin was tossed 100 times and it fell one side (either heads or tails) 70 or more times, then you can be more than 99.9% sure the coin is biased, as 70 or more heads, or 70 or more tails is very unlikely to happen by chance.
In statistics, a result is called statistically significant if it is unlikely to have occurred by chance and so there is likely to be an underlying reason for the result. In the first case, the 7 heads is not statistically significant, as the probability of this happening by chance is not small (it is 0.3428). In the second case, when the coin is tossed 100 times, the probability of 70 heads happening by chance is less than 0.0001, so the 70 heads is most unlikely to be due to chance and so is termed statistically significant.
In any large database of games, you will find that there are often several moves played. In my database of over 3 million games, every one of the possible 20 opening moves has been played at least once. The tree window will show you the scores - a move that scores better than another will often be more attractive for a player. But difference in scores can be due to chance and does not necessarily mean there is any underlying reason that one moves scores better than another. ChessDB can tell you if the differences in scores between two moves is unlikely to be due to chance alone and so there is likely to be an underlying reason. It can not tell you what the reason is - simply whether or not there is one. The most obvious reason for one move scoring better than another is that is is a better move, but there can be other reasons too. If the moves are predominantely from one player, then it would reflect that players abiltiy with that move, rather than the geneal quality of the move.
How to compare the statistical significance of scores in ChessDB
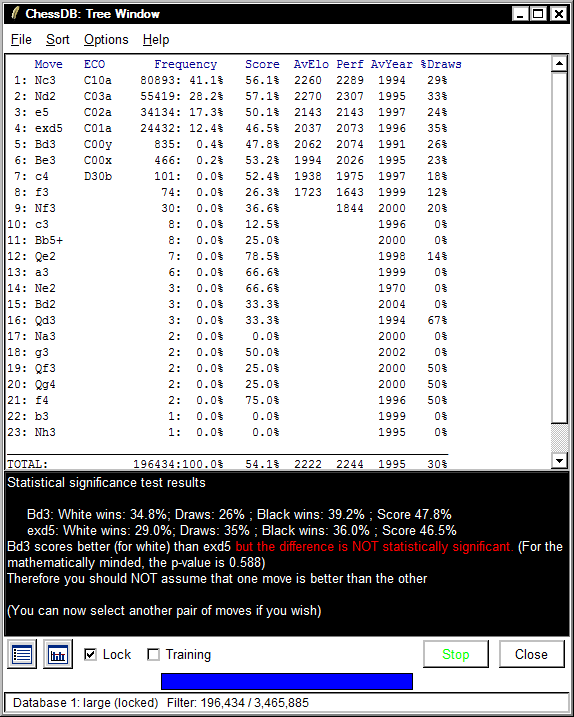
If you right-click on any two moves in the tree window,
ChessDB will tell you whether the differences in score are statistically significant or not.
If the difference in score, or any larger differences has a
probability of occurring by chance of 0.05 or more, then
ChessDB reports the result is not statistically significant, and prints this in red, as shown below.
If the probability of the observed difference in score
occurring by chance is less than 0.01,
then ChessDB says it is highly statistically significant and
prints the result in green, as shown at the top of this
page. If the probability that the difference in score,
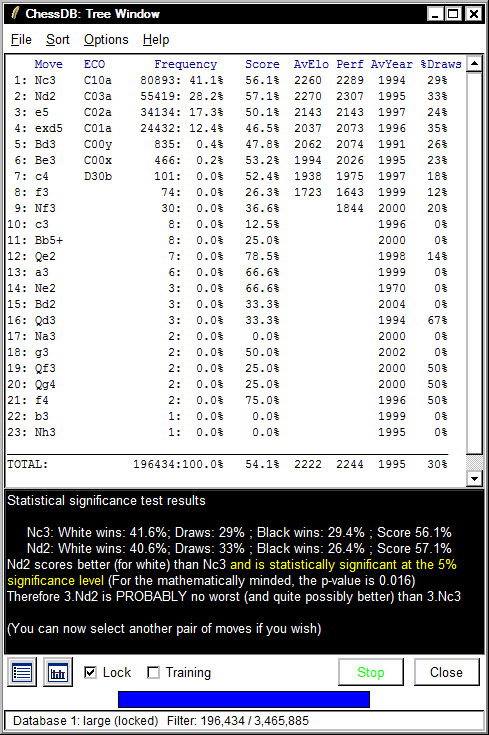
or any larger difference occurring by chance is between
0.01 and 0.05, then ChessDB says this is statistically
significant and prints this in yellow as below, where the moves
3.Nd2 and 3.Nc3 were compared in the French Defence (1.e4 e6 2.d4 d5).
The probabilities of 0.05 and 0.01 were chosen somewhat arbitrarily,
but they are commonly used in statistics. ChessDB
prints the p-value, which is the probability the
differences in score, or any larger difference would occur by chance. The
direction of the difference is not specified.
Comparistion of 1.e4 and 1.Na3 (the highest scoring move).
The data in my database at the start of the game showed the move scoring highest for white is 1.Na3! That goes against the generally held views on opening theory, which state white should try to control the centre. Putting a knight on the a-file certainly does not do that!
Comparing the moves 1.Na3 (score = 60.2%) and 1.e4, (score = 53.0%) we see a large difference in score, of 60.2-53.0 = 7.2%. If you could score more than seven percent better with 1.Na3, then it would be very useful. But if analyse this in ChessDB, we soon find that the differences in score are not statistically significant as the probability of a result at least as extreme occurring by chance is quite high (0.564).
Comparion of 1.e4 and 1.d4 for a first move
Comparing the moves 1.e4 and 1.d4 in my database, we find that the difference in score, which is 1.7% (53% for 1.e4 and 54.7% for 1.d4) is highly statistically significant, with a p-value of less than 0.01, so we can be more than 99% sure this result is not due to chance alone. ChessDB does not tell you why 1.d4 scores better than 1.e4, but the 1.7% difference is most unlikely to be due to chance alone. It does rather bring into doubt the statement of Fischer that 1.e4 is best by test. Whilst it may have been for him, it does not appear to be true when a large number of games are analysed.Notes on statistical significance
- The fact there is a statistical significnace between the scores of two moves, tells us nothing about the size of the difference. In some cases a difference in score of 0.1% may be statistically significant, but such a difference in score is of little practical importance, as it would only affect a result in one game in every 1000, so it would be a waste of ones time to spend much time on a new repetoire which scores only 0.1% better.
- A result is more likely to show statistical significance if the database is large. Unfortunatly, as databases become large, their quality tends to fall.
- Since this is a new feature, its limitations are not fully understood. Experience will no doubt improve upon this situation.
Information in the Tree Window
At the bottom of the tree window we see there are 3,465,885 games in the database, of which virtually all (3,465,514) are in the tree window. The few that are not included do not have the normal start position, so might be games with material odds, Fischer Random games, tactical positions or any other reason the games do not have a normal start position.
Information about the average Elo and the average date are given too. (There is currently a bug which means one of these may be wrong on very large databases due to an internal overflow. I've only observed this on a database of more than 5 million games).
Sorting the Tree Move List
By default, the moves listed in the tree are sorted by frequency (how often each move has been played). This is usually the most useful, but other options are available from the Tree window Sort menu. Sorting by score (which is always from White's perspective is very useful too, as it shows what moves score well.
The Tree Graph
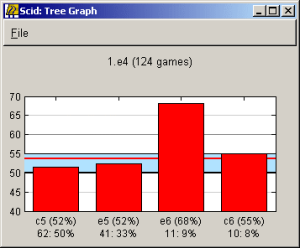 ChessDB can display the score column of the Tree as a graph.
In the Tree window, select the File / Graph window menu
command or press the
ChessDB can display the score column of the Tree as a graph.
In the Tree window, select the File / Graph window menu
command or press the  button. You should see a new window like the screenshot here, which
(in this case) shows that in the position after 1.e4, the moves
c5 and e5 have scored around 52% for White in this database,
but Black has done very poorly
(White has scored 68%) with 1...e6, the French defence.
This also shows that you
must be wary of statistics based on a small number of games, as 1.e4 e6
has only been played 11 times in this database.
button. You should see a new window like the screenshot here, which
(in this case) shows that in the position after 1.e4, the moves
c5 and e5 have scored around 52% for White in this database,
but Black has done very poorly
(White has scored 68%) with 1...e6, the French defence.
This also shows that you
must be wary of statistics based on a small number of games, as 1.e4 e6
has only been played 11 times in this database.
Note that scores are always from the White perspective, even when Black is to move. The range 50% to 55% is given a light blue background to help it stand out. In master level chess White scores about 54-55% on average, so a bar much higher or lower than the top of the blue area represents a move that has had unusually good or poor results. The Tree graph also draws a red line representing the average (weighted mean by frequency) of all moves from the current position, so you can see how each move compares to the mean.
The Best Games List
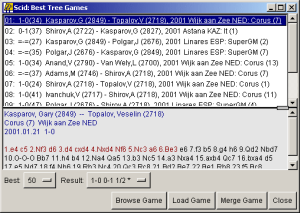
The Best games list shows a list of the "best" selected games that
reach the current position. You can open it from the Tree window
File / Best games list menu command or the
 button.
button.
The "best" games are defined to be those with the highest combined Elo rating, so games between strong grandmasters will appear at the top of the list. There are two menubuttons in the Best games list window that you can use to alter the size of the list or restrict the list to contain certain results (such as White wins only).
The lower pane of the Best games list shows a preview of the currently selected game. For each game in the list, you can browse it (that is, view it in its own window without affecting the currently loaded game), load it, or merge it as a variation of the current game. This last option is useful for annotating a game by adding references to master games that reached the same opening variation.
Locking the Tree Window
You may find that you often want to browse games in one database, while viewing the Tree information of another database. For example, you may be browsing games in a small database and also have open a much larger reference database that you'd like the Tree window to use.
You can do this by locking the Tree to one database. To lock the tree, first make sure the database you want the Tree to use is selected, then press the Lock checkbox in the Tree window. Then switch to any other database, and the Tree will continue to use the locked database until you unlock it.
If you would like to contribute to the tutorial or see anything that should be updated, corrected or improved, please contact David Kirkby. But please note David only speaks English.

Website administered by Dr. David Kirkby
This page was last modified: September 16, 2007. 10:41:41 am GMT